

Study population
This study is a single-center cohort study conducted at Zhongnan Hospital of Wuhan University. Emergency medical records from January 1, 2015, to December 31, 2022, of patients using “chest pain,” “chest tightness,” and “palpitations” templates were collected to establish training and testing datasets for model development. For prospective validation, records from January 1, 2024, to March 31, 2024, corresponding to the on-duty days of participating physicians, were included.
Zhongnan Hospital of Wuhan University is a provincial Class-A tertiary teaching hospital. As the core component of the hospital’s chest pain center, the ED plays a vital role in the assessment of daily ST-segment elevation myocardial infarction (STEMI) patients, assisting the cardiology department in performing over 200 emergency percutaneous coronary intervention (PCI) procedures annually.
The emergency department at Zhongnan Hospital of Wuhan University uses structured EMR templates to ensure a systematic and comprehensive documentation by healthcare providers. The attending physicians select the template based on the patient’s chief complaint at presentation. Given the lexical diversity of the Chinese language, this study includes all EMR templates related to chest discomfort, specifically “chest pain,” “chest tightness,” and “palpitations.”
Exclusion criteria are as follows: patients younger than 18 years old; medical records with chief complaints irrelevant to the study focus (e.g., medication refills, trauma); duplicate records of visits; and records missing the year of consultation.
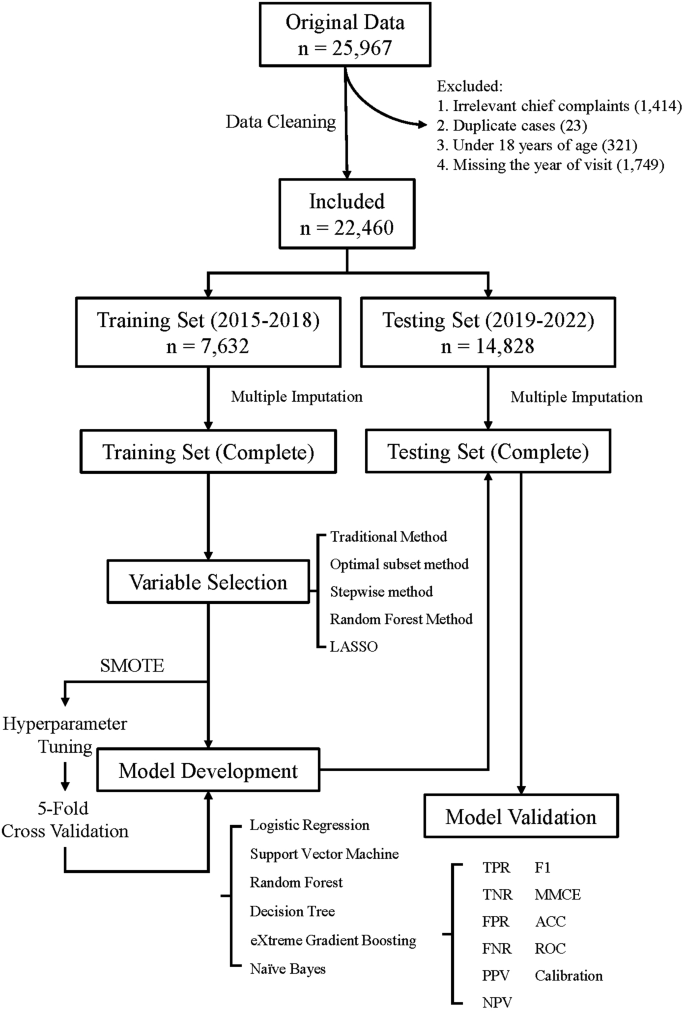
The flowchart outlining the construction of the machine learning model in this study is shown in Fig. 1.
Ethical review of clinical research
This study has been approved by the Ethics Committee of Zhongnan Hospital of Wuhan University (retrospective: Ethics Approval No. 2024028 K; prospective: Ethics Approval No. 2024094 K). Given that this study does not involve experimental research on human subjects and poses no significant risk to participants, the Ethics Committee has granted a waiver for informed consent. This segment of the study adheres to the TRIPOD guidelines (Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis).
Annotation of chest pain risk stratification
According to the definition provided in the 2021 Guideline for the Evaluation and Diagnosis of Chest Pain jointly issued by seven major associations, including the American Heart Association (AHA) [2], the primary outcome in this study was high-risk chest pain diagnoses documented in emergency medical records. These included ACS, AAD, PE, esophageal rupture (ER), and tension pneumothorax. Patients categorized under this group were considered high-risk and potentially faced life-threatening conditions, while others were labeled as non-high-risk.
The emergency diagnoses were made by experienced physicians after thoroughly evaluating patients’ vital signs, symptoms, laboratory test results, electrocardiograms, imaging findings, and other relevant examinations conducted during their emergency department visits. As such, these diagnoses were regarded as endpoint indicators reflecting patients’ conditions during that specific period. Additionally, given the retrospective nature of the model development phase in this study, the evaluation of content and outcomes relied on archived data. The diagnoses recorded in emergency medical records represented real-time clinical judgments and diagnostic conclusions made by physicians, free from the potential bias introduced by subsequent prospective evaluations. Thus, blinding was not required during data processing. This approach ensured an objective assessment of the recorded data, unaffected by prognostic speculation, thereby maintaining the integrity of the evaluation process.
Selection of independent variables
After data preprocessing, the dataset was screened for the following variables (numbers of variables in total: 87): symptoms, chest pain intensity, vital signs, demographic data (sex and age), self-reported past health status, surgical history, history of coronary artery disease, chronic disease history, medication history, allergy history, smoking history, alcohol consumption history, and the location of referred pain. Symptoms and physical examination findings were derived from EMRs documented by physicians during patient consultations. Vital signs were measured using bedside monitors or related medical devices and manually entered into the patient’s medical records. The patient’s medical history was obtained during nurse triage and emergency department visits. In the dataset, the recorded variable refers to sex (biological attribute) rather than gender.
Initially, all categorical variables in the dataset underwent a preselection process, retaining only those with a positive rate greater than 0.05% (n = 27). This step aimed to exclude categorical variables with very low frequencies in the sample, thereby reducing model complexity and avoiding overfitting. Then, we employed various feature selection methods including traditional methods (t-tests for continuous variables and chi-square tests for categorical variables), Least Absolute Shrinkage and Selection Operator (LASSO), optimal subset selection, stepwise selection, and random forest methodology.
Construction of machine learning models
The original dataset was split chronologically into two subsets based on visit year for temporal validation: data from 2015 to 2018 were used for model development (training set), and data from 2019 to 2022 were used for model testing (testing set). To avoid data leakage, multiple imputation was performed independently within each subset. Predictor variable selection and model construction were carried out using the 2015–2018 training set, and model performance was evaluated on the 2019–2022 testing set. The ROC curves of the models were plotted using the entire testing set, while five-fold cross-validation was employed to validate other evaluation metrics of the model.
Synthetic Minority Oversampling Technique (SMOTE) has been applied to address class imbalance in the training set. Specifically, a sampling rate of 3.4 was used to generate synthetic samples for the minority class, with 5 nearest neighbors considered for interpolation.
In this study, six types of machine learning techniques were used for model development: Logistic Regression (LR), Decision Tree, Naive Bayes, Random Forest (RF), eXtreme Gradient Boosting (XGBoost), and Support Vector Machine (SVM). For prospective validation, the XGB model, which demonstrated the best overall performance, was compared with the HEART score and nurse triage results.
This study employs a nested cross-validation approach for the automated selection of hyperparameters. During model development, a random search strategy is used for hyperparameter tuning.
The model development and validation (testing) process employs a repeated five-fold cross-validation method, repeated ten times.
Model performance evaluation metrics
The following metrics are used to evaluate the model’s performance: Mean Misclassification Error (MMCE) and Accuracy (ACC); the Receiver Operating Characteristic (ROC) curve; the calibration curve; Positive Predictive Value (PPV) and Negative Predictive Value (NPV); True Negative Rate (TNR, also known as specificity), False Negative Rate (FNR), False Positive Rate (FPR), True Positive Rate (TPR, also known as sensitivity); and the F1 score.
Prospective validation of the machine learning model
To conduct a prospective validation of the model’s performance, we used a non-interventional, prospective data collection method to gather a small-scale dataset from patients.
During the data collection process, attending physicians in the ED will act as data collectors. To ensure efficient and accurate data collection, an online patient information collection form was created based on the model’s variables. In this form, binary variables were set up for the physicians to select predefined labels “0” and “1” to accurately record patient information. For numerical variables, the physicians manually inputted data. A researcher conducted daily checks on the data collected for that day. This process included retrieving patient medical records and cross-referencing them with the results entered by physicians.
Additionally, this data collection also included the triage information recorded by nurses and data related to the patient’s HEART score for comparison and reference. Given the subjectivity in parts of the HEART score such as “History” and “Risk factors,” a detailed reference table from the Heart-Pathway study [9] has been established to guide annotators. The annotation of the HEART score was performed by two specially trained physicians.
The results of the prospective pre-experiment included an evaluation of the model’s predictive performance, as well as a comparison with nurse triage outcomes and HEART scores. Original nurse triage categorizes patients into four levels. In this study, nurse triage levels 1 and 2 were combined and labeled as “high risk”, while levels 3 and 4 were marked as “non high risk.”
Our department referenced the French triage guidelines and referred to the Guidelines for the Classification of Emergency Patients issued by the Ministry of Health of China in 2011. The quantified four-level emergency pre-triage standards assess “basic vital signs” collected based on emergency symptoms of systemic and specialty-related diseases, categorizing emergency patients as follows:
-
1.
Level I: Critical patients – Conditions that may immediately threaten the patient’s life and require life-saving interventions.
-
2.
Level II: Severe patients – Conditions that may progress to Level I in a short time or result in severe disability.
-
3.
Level III: Urgent patients – Conditions with no immediate life-threatening or severely disabling signs, a low likelihood of progression to severe disease or complications, but require emergency care to alleviate symptoms.
-
4.
Level IV: Non-urgent patients – Conditions without acute symptoms, minimal or no discomfort, and a clinical judgment of requiring limited emergency medical resources.
Level I and II patients are immediately transferred to the resuscitation room for treatment. Level III and IV patients wait in the designated waiting area.
Analytical methods
All analyses were performed using R Studio software (version 4.2.3). Continuous data were presented as mean values with standard deviations. Categorical data were presented as frequencies and percentages. Continuous variables were normalized using the min-max standardization method to meet the requirements of algorithms that require standardized numerical predictors. The agreement between nurse triage results and model predictions was assessed using Cohen’s Kappa statistic. The level of statistical significance was set at p < 0.05.
link